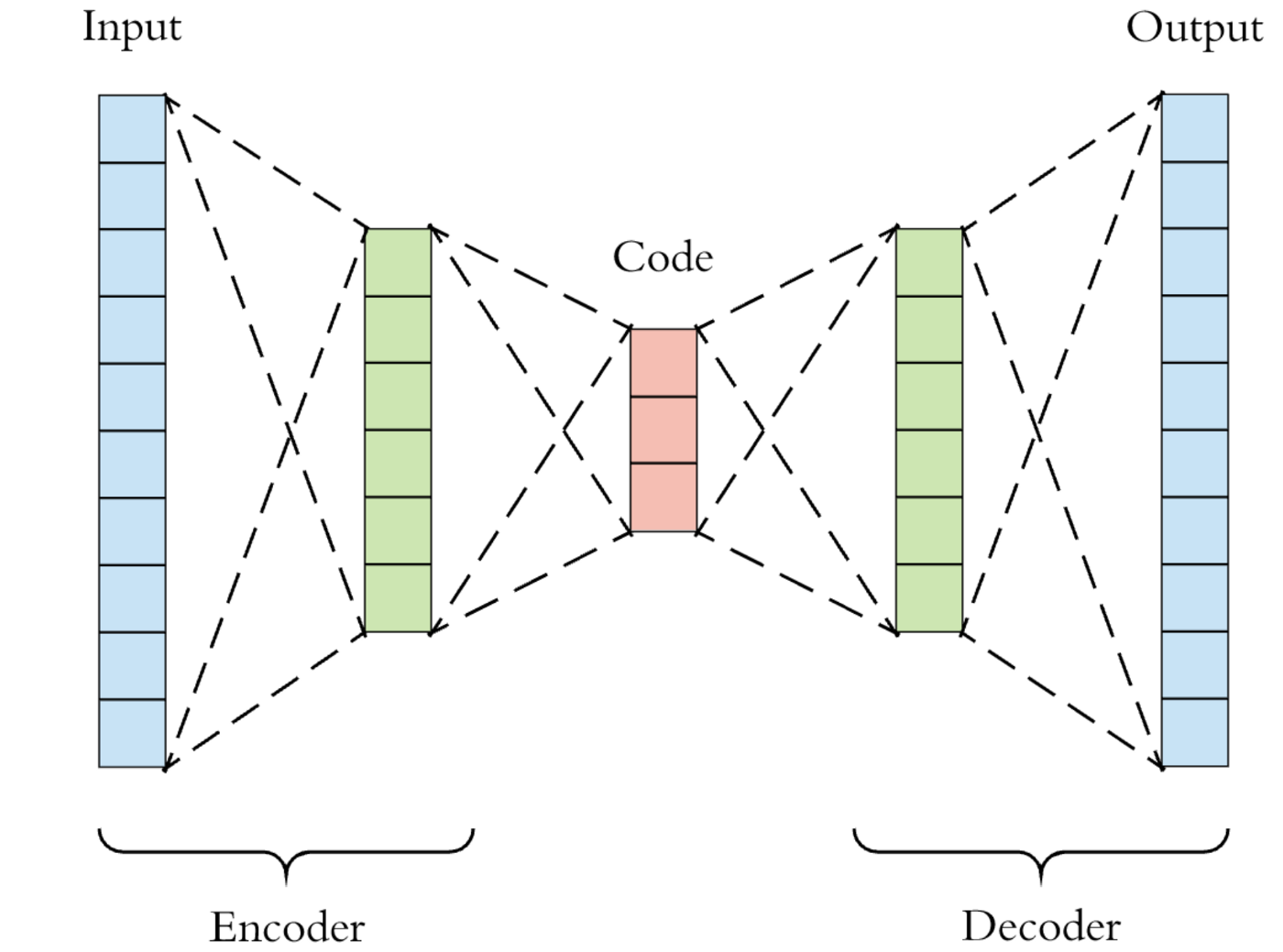
This idea is encompassed in the concept of a latent space, or a space of numbers in any amount of dimensions that can represent information. An example of this is how I can't give you [-1.69, 4.20, and 3.901] and then tell you that it matches with a photo of the digit three, and then ask you what digit you will get with [1.69, 4.20, 3.901] (first number is now positive). But neural networks can, and that's fascinating.
In autoencoders, you have a middle layer (also called the coding layer), that contains a set amount of numbers. These numbers are then fed into even more layers at the end to recreate the original image. This means that just based on a few numbers, it can recreate an entire image! Isn't that amazing that it can just use numbers, and it learns what the numbers even mean?
We trained an autoencoder with just two codings, and it was able to produce some pretty realistically outputs. We then made videos, where we took random codings and values near that coding and saw how the autoencoder outputs would change as we increased the coding in any of the dimensions. This gave us a glimpse into the brain of a neural network. Did I mention it was trained by SeaLion?
We also plotted all of the 2D codings on a graph and got this:
